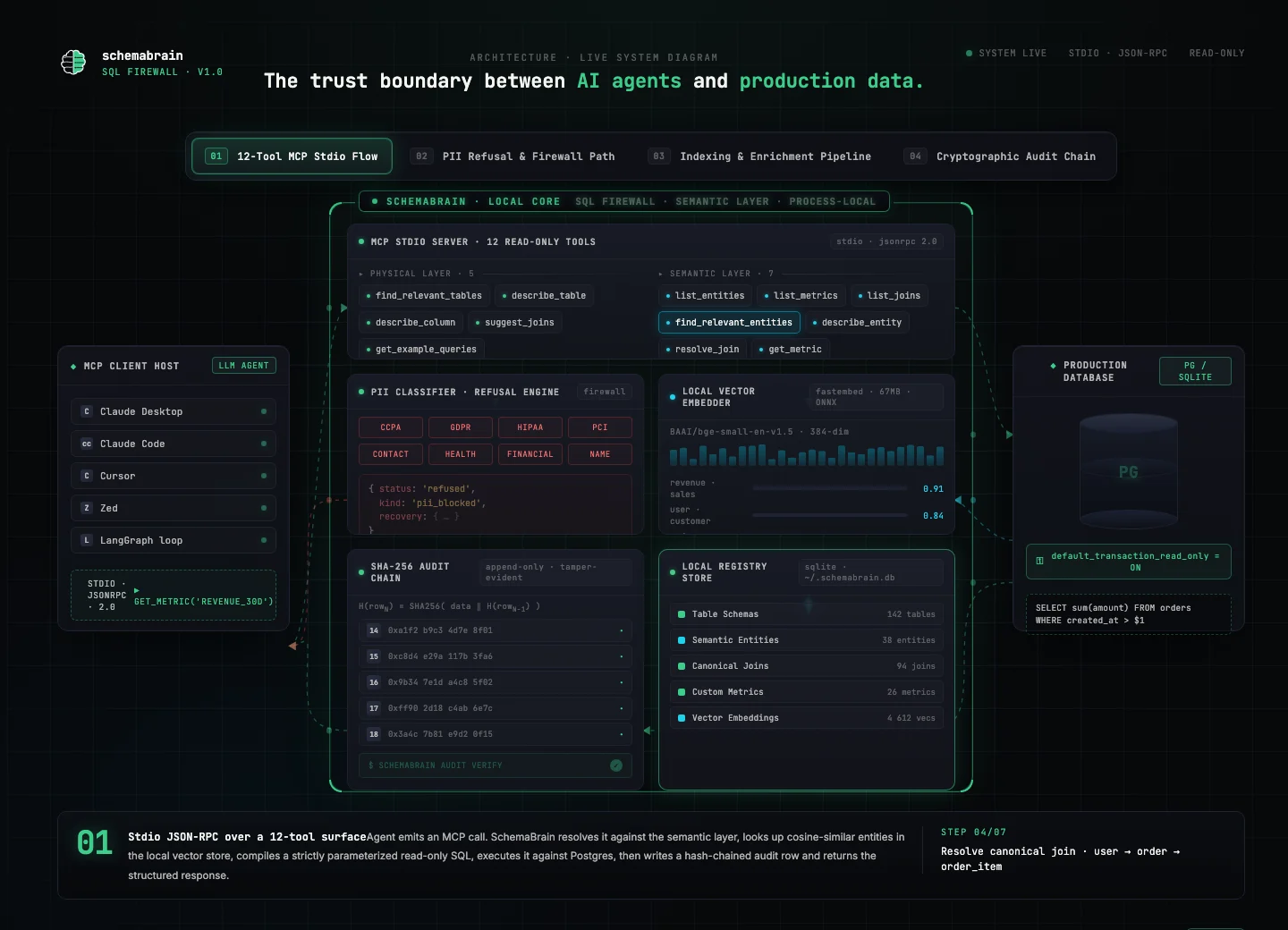
Three boxes, one trust boundary. The agent on the left, your Postgres on the right, SchemaBrain in the middle — every tool call lands in the audit chain before the parameterized SQL leaves the firewall.
find_relevant_tables, describe_entity, get_metric, and so on — none of which accept arbitrary SQL.
In the middle, SchemaBrain resolves each tool call against the local SQLite store (cached schema + entities + metrics + joins), compiles strictly-parameterized read-only SQL, and writes a hash-chained audit row before the query leaves the boundary. The four mechanisms that make this a firewall — read-only by architecture, PII taxonomy with compile-time propagation, tamper-evident audit chain, and structured recovery envelopes — all live inside this box. None of them can be flipped by a prompt.
On the right, the agent’s effective surface on your Postgres is the parameterized SQL SchemaBrain emits. The session is opened with default_transaction_read_only=on and a NullPool connection pool, so no session-level flag survives long enough to be exploited and no two tool calls share a connection. The same architecture works against any SQLAlchemy-compatible source; the v0.5 release targets Postgres because that’s where the operator demand is.
How SchemaBrain is put together, the contracts the tool layer keeps, and what
“validated” actually means today.
The pipeline
The pipeline is single-process and synchronous. No Celery, no Redis, no Qdrant. The store is one SQLite file you can
cp to back up, sqlite3 into to inspect, or rm to start over.Cache-aware re-indexing
Re-runningschemabrain index against an unchanged schema costs $0.00 in
LLM calls. Each column has a content-addressable fingerprint:
The cache key includes
prompt_version so a prompt change correctly
invalidates everything.
How retrieval works
find_relevant_tables runs cosine similarity between the query embedding
and every stored column embedding. Per-table score = MAX cosine across the
table’s columns (sparse-relevance heuristic — one highly-aligned column is
strong evidence). Tables with no matches above zero are dropped; ties break
alphabetically by qualified name.
Weak matches return data, not errors
If we returned an error for “no good match,” the agent couldn’t tell what the indexed schema contains — and listing what’s available is one of the most useful things the agent does on adversarial questions (“there’s no payments table; here’s what we DO have”). Score thresholds are the agent’s call, not the tool’s. In our testing (Claude Haiku 4.5 + Sonnet 4.6), the agent correctly judged “0.74 max score = the search reaching, not a real hit” and answered honestly. A futurematch_quality enum may land in v1 if smaller models struggle to
reason about raw scores.
Query-log mining
Schema introspection tells the agent what exists; query-log mining tells it what runs.schemabrain mine-queries reads pg_stat_statements,
normalizes each SQL text, and stores it alongside an observation count,
first/last seen timestamps, sensitivity tag, and PII category set. The
get_example_queries MCP tool surfaces those examples per table so the
agent can pattern-match on real usage instead of guessing column shapes
from names alone.
Mining is opt-in and idempotent. Run it once for a snapshot, or on a
schedule for living usage data. Until it has run, get_example_queries
returns status: empty with a recovery hint pointing the agent at
describe_table — the agent never gets a hard failure for an
unpopulated cache.
Cost model
Perindex run, with the default Haiku 4.5 + local embeddings:
Both cost and time scale near-linearly with column count, not table
count: at the measured Pagila anchor the per-column cost is ~$0.00034
and per-column time is ~1.2 seconds. The
extrapolated rows assume that ratio continues; production-scale anchors
will tighten or revise it.
Partitioned tables are deduplicated automatically
Declarative partition children share an identical column structure with their parent, so enriching each one separately is purely wasted work. The Postgres connector filters them out atlist_tables() time using
pg_class.relispartition. On Pagila this dropped the index from 22
tables / 129 columns to 15 tables / 87 columns — a 34% cost reduction
and a 50% time reduction vs the naive reflection.
get_table() stays permissive: if a caller explicitly asks for a
partition child by name, they still get it. Only bulk listing skips them.
Eval
Bundled 10-question golden set on the e-commerce fixture, with the local embedding retriever:
Reproduce:
Retriever Protocol
implementation against any golden set. Bundled with two examples
(golden_sets/ecommerce.json — the --golden default — and
golden_sets/saas.json); bring your own golden_sets/<your-schema>.json
for your real schema. The
BIRD Mini-Dev automated benchmark is on the v0 roadmap for cross-comparable
text-to-SQL execution accuracy.
What’s validated
As of v0.6.0, against two reference anchors — the e-commerce fixture (8 tables / 39 columns) and the Pagila DVD-rental sample (15 tables / 87 columns after declarative-partition deduplication; 22 / 129 raw). A SaaS demo pack (12 tables / 84 columns) ships as the default bundled fixture, exercised by the pre-publish smoke — PII refusal, audit-chain integrity, and refuse-then-pivot recovery over the headless Anthropic SDK:- ✅ Indexes Postgres 16 schema with FK-aware introspection (both anchors)
- ✅ Partitioned tables are deduplicated; only the parent is enriched
- ✅ Partition-parent FKs unioned from children (Pagila pattern) so declaratively-partitioned tables aren’t seen as relationship-less
- ✅ Junction (M:N) tables are detected structurally; descriptions
explicitly warn that joining through them multiplies result rows;
list_joinssynthesises logical bridges across junctions - ✅ Generates LLM descriptions via Anthropic Claude (Haiku 4.5 default;
cryptic columns opt into Sonnet 4.6 via
--enable-sonnet) - ✅ Local embeddings via
fastembed(no second API vendor) - ✅ All 12 MCP tools tested via Claude Desktop AND headless Anthropic SDK,
on both anchors. The 12:
list_entities,list_metrics,list_joins,describe_entity,describe_table,describe_column,find_relevant_tables,find_relevant_entities,suggest_joins,resolve_join,get_example_queries,get_metric - ✅ Adversarial questions handled honestly (“not in indexed schema” with
explicit qualifier) — Pagila negative-question test correctly distinguished
internal
payment_idfrom external payment-processor transaction IDs - ✅ Multi-hop join discovery via
suggest_joins(Pagila: rental → customer → address path returned correctly) - ✅ Query-log mining via
pg_stat_statements;get_example_queriesreturns observed SQL with PII tagging - ✅ Cache-aware re-index ($0 on unchanged schemas)
- ✅ Fresh-machine quickstart works from a stripped shell
- ✅ Continuous integration (lint + unit + integration with a 99% coverage
gate over the full test suite on
main)
M:N caveats are surfaced in junction-table descriptions
Junction (M:N association) tables are detected structurally — composite primary key with all PK columns being FK sources to ≥2 distinct target tables — and that detection becomes part of the column-enrichment prompt. The resulting descriptions explicitly state that joining through the junction multiplies result rows, surfacing the double-counting risk downstream agents need. Example, generated on Pagila’sfilm_category (composite PK on
(film_id, category_id) with FKs to film and category):
film_id: “Identifier for a film in this junction table that links films to their categories; joining through this table multiplies rows by category count per film”
category_id: “Identifies the category assigned to a film in this M:N junction table; joining through multiplies result rows”Whether the calling agent surfaces a separate Caveat: block in its final answer depends on the question:
- When the user asks about caveats (“what should I watch out for”),
Claude Haiku 4.5 reliably writes an explicit M:N caveat as the first
numbered item, names the consequence (“counted in both category
totals”), and suggests
DISTINCTor business-rule clarification as the fix. This is gold-standard behavior. - When the user just asks for the SQL with no priming, surfacing varies. Across multiple Haiku runs on identical inputs, sometimes the agent mentions M:N inline as a parenthetical, sometimes it omits it. The variance is downstream of LLM sampling, not SchemaBrain.
describe_column / describe_table. Agents
performing serious analysis should be prompted to surface them.
Self-referential association tables (both PK columns FK to the same
target) do not currently qualify as junctions under this heuristic;
revisit if real-world schemas ever rely on the pattern.
Independent SQL validation (per Setup) remains the right
backstop for production queries.
Scalability frontier
SchemaBrain has three known architectural ceilings. None trip on today’s real workloads but each will trip on extreme or adversarial inputs. We publish them up front because an honest “here is where we will hurt” is a better trust signal than a vague “scales well.”
Each swap is localised to one implementation file behind a Protocol that
already exists. The migration risk is bounded; the work is not free.
What this looks like in practice: a 200-table production schema is well
inside today’s envelope (the cost-model table above extrapolates to
~$0.50 and ~30 minutes). A 5,000-table data warehouse will hit one or
two of these ceilings; the operator should expect to migrate to the
swap path and we should expect to do that work.
The detailed ceiling analysis — triggers, swap plan, risk discussion —
lives in an internal memo that is not part of the OSS distribution.
What’s coming after v0.5
The v0.5 release ships the four load-bearing safety mechanisms — read-only by architecture, the 12-category PII taxonomy, the hash-chained audit log, and the structured recovery envelope. The roadmap from here is incremental hardening + scope expansion, not a re-architecture:- More database engines — MySQL and SQLite source support (currently Postgres-only). Same firewall posture, broader applicability.
- EXPLAIN-based cost cap — extend the current
--statement-timeout-msand--max-rows-per-resultguards with a pre-execution cost estimate, so an expensiveget_metriccall is refused before the source is touched. - Content-aware PII classification — extend the name-based classifier with
sample-value inspection. Catches columns where the rule table would match the
content (e.g. a free-text
notescolumn holding the occasional email or SSN) but not the column name. - HTTPS transport — alongside the current stdio transport, for hosts that can’t launch a subprocess (e.g. ChatGPT Custom Connector).
Next steps
MCP tool reference
Per-tool signatures, response shapes, and refusal contracts.
Read-only by architecture
Why writes are impossible at the type level, not the trust level.
Threat model
Full attack-surface walk-through with code citations.
Charter v1.2
The contract every MCP tool implements — status taxonomy, envelope shape, recovery hints.